
Indicizzare i Blob Storage con Azure Search
Nel mondo cloud di Microsoft i blob di Azure Storage sono lo strumento principale da usare per depositare file in modo sicuro, affidabile e scalabile. Si accedono via REST e con qualsiasi linguaggio, hanno uno spazio infinito (o quasi) e sono ampiamenti sfruttati dall'infrastruttura stessa.
Sulla stessa piattaforma, Azure Search č invece lo strumento dedicato ad indicizzare e offrire API REST per effettuare ricerche, suggerire e categorizzare documenti in senso lato. Entrambi gli strumenti possono essere usati congiuntamente perché non solo Azure Search č in grado di ricevere contenuti con uno schema da noi indicato, ma anche disporre di indexer che vadano a pescare contenuti dai blob stessi. Il motore č in grado infatti di indicizzare i contenuti di file come PDF, DOCX, XSLX, ZIP, XML e HTML, per citarne alcuni, e catturarne i metadati principali, come il titolo, l'autore e la lingua.
Collegare uno storage alla ricerca č ancora piů facile. E' sufficiente recarsi sullo storage di riferimento e accedere alla sezione Add Azure Search. Ci viene proposto il servizio di Search da collegare, che deve giŕ esistere.
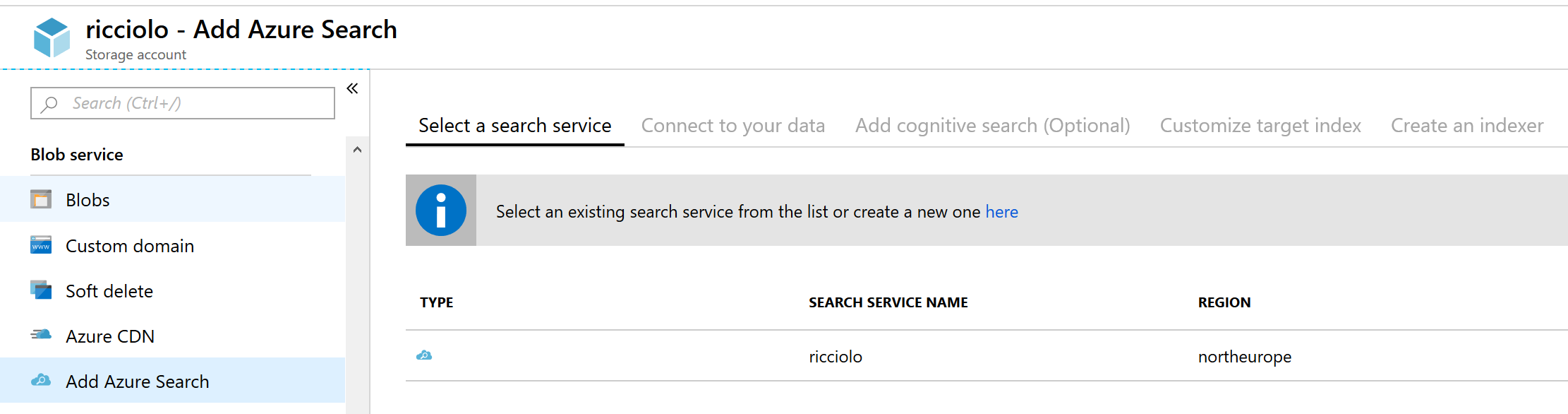
Il wizard ci porta poi a selezionare lo storage e il container da indicizzare, eventualmente filtrando per cartella. Possiamo decidere se indicizzare solo i metadati o anche il contenuto. Se siamo certi del tipo di file possiamo indicare anche il parsing mode, su JSON o Plain text, altrimenti lasciamo il default che lascia il compito al motore di capire il tipo di parser piů adatto.
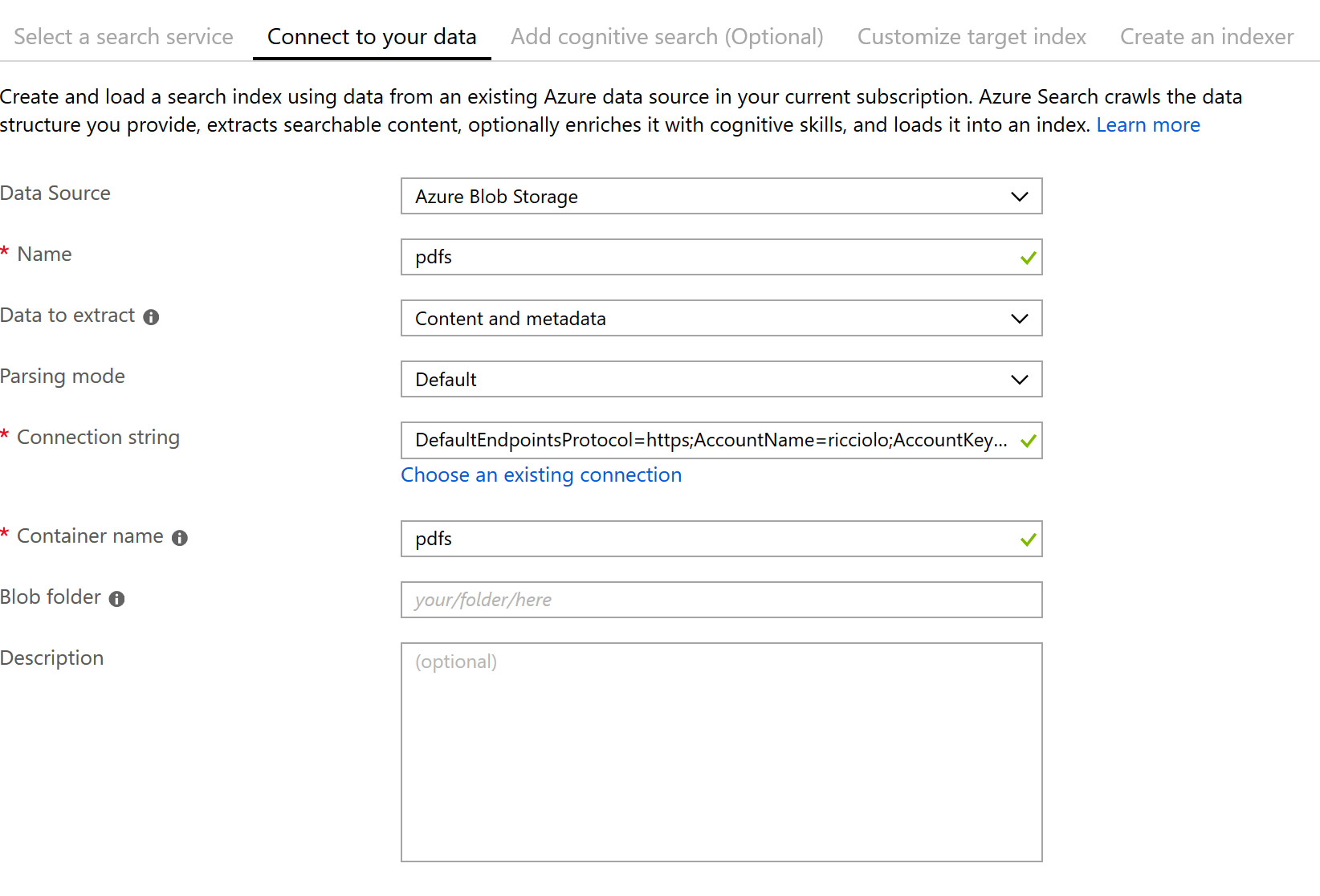
Dopo un'analisi del container, il quale deve obbligatoriamente avere uno o piů file campione, ci viene proposto il tipo di indice che verrŕ creato: il nome, la chiave di riferimento (il path del blob) e i cambi individuati con il tipo di operazione che vogliamo supportare.
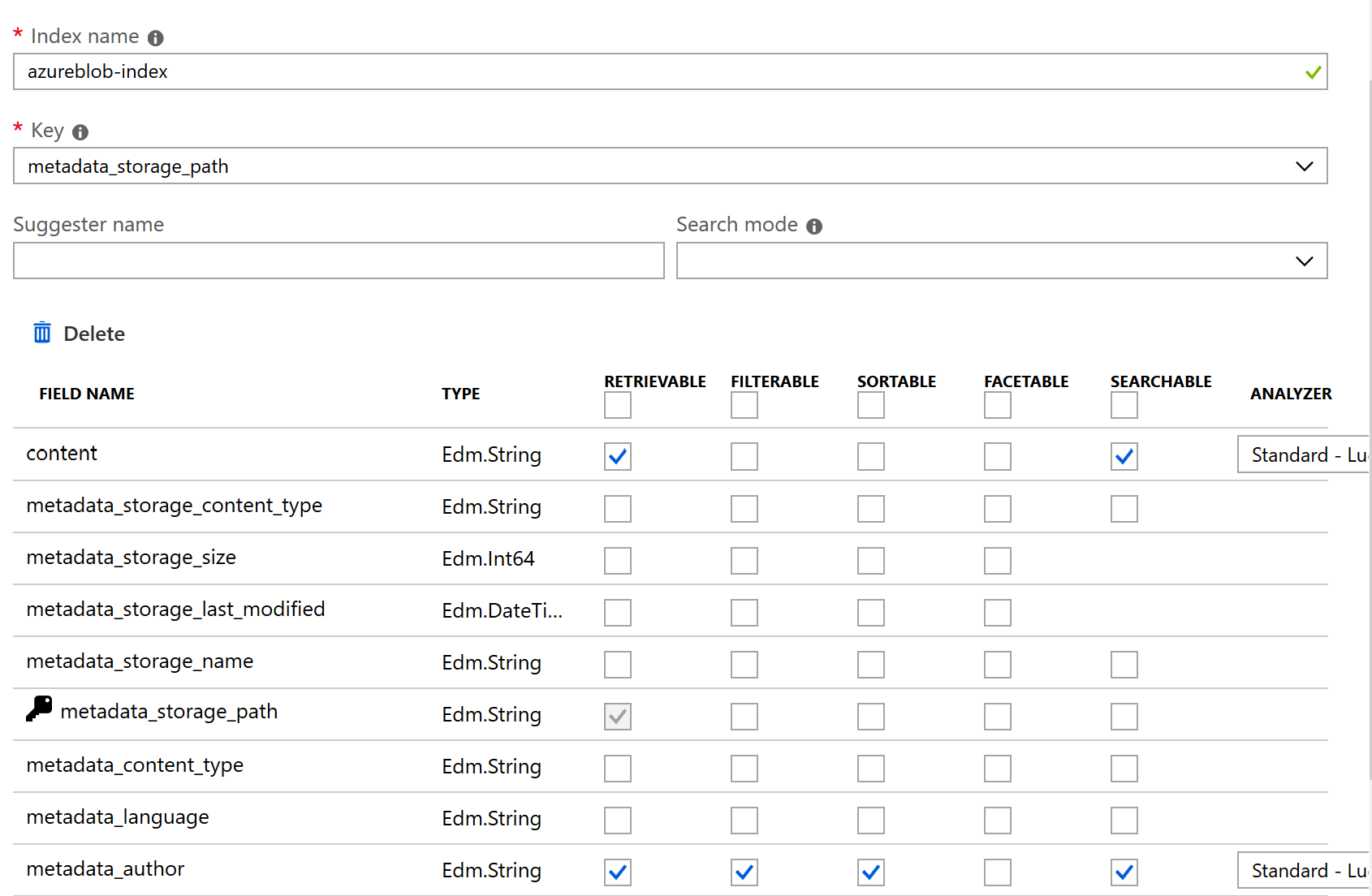
Come ultimo step dobbiamo configurare l'indexer, cioč con quale frequenza indicizzare i nuovi blob o quelli cambiati, operazione effettuata tramite il LastModifiedDate del blob.
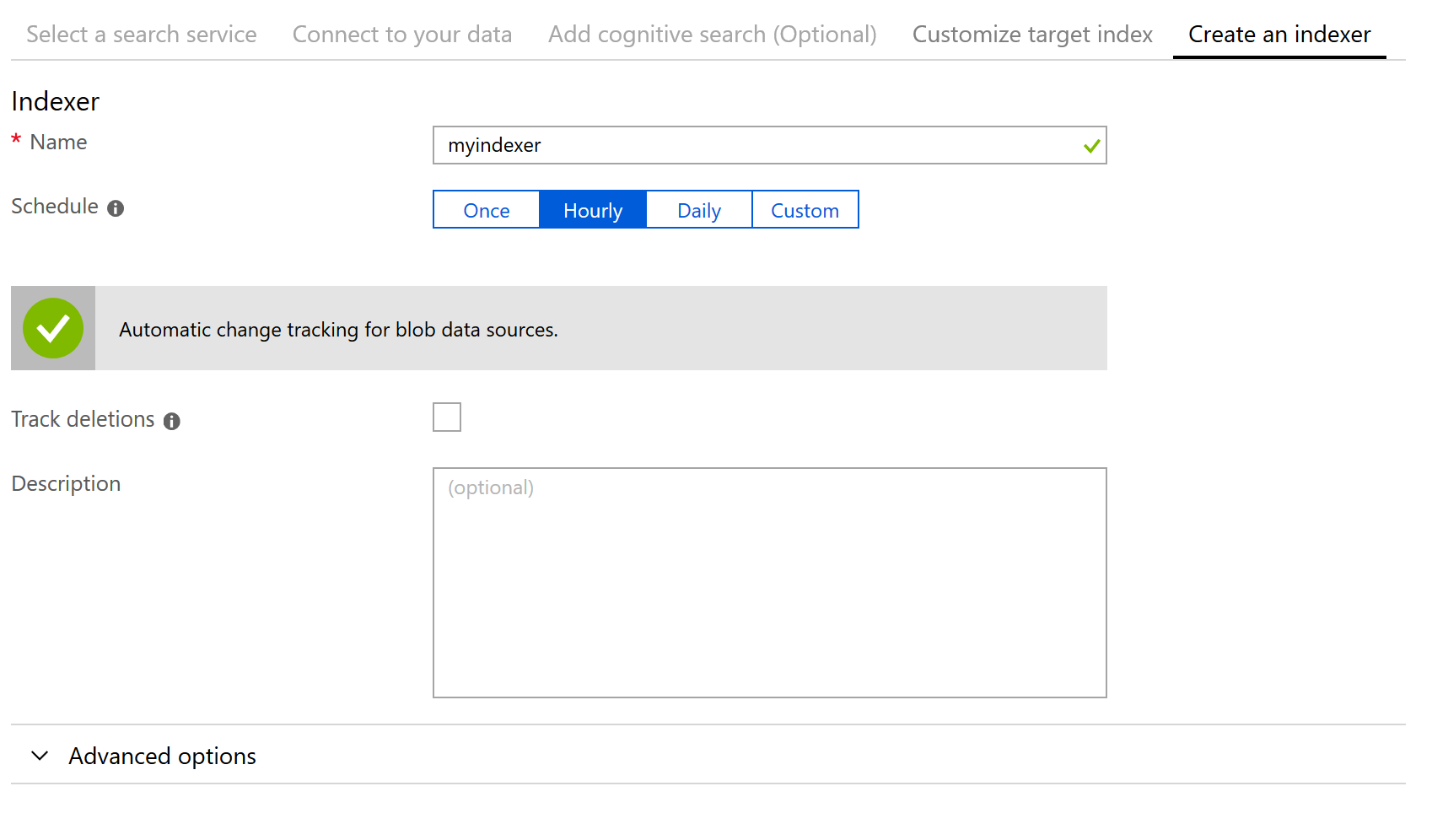
Fatta quest'ultima operazione non ci resta che andare nella sezione Azure Search e vedere che sono stati creati un index, un indexer e un data source. Possiamo procedere a piů indexer per ottenere piů potenza e partizionare i documenti da processare.
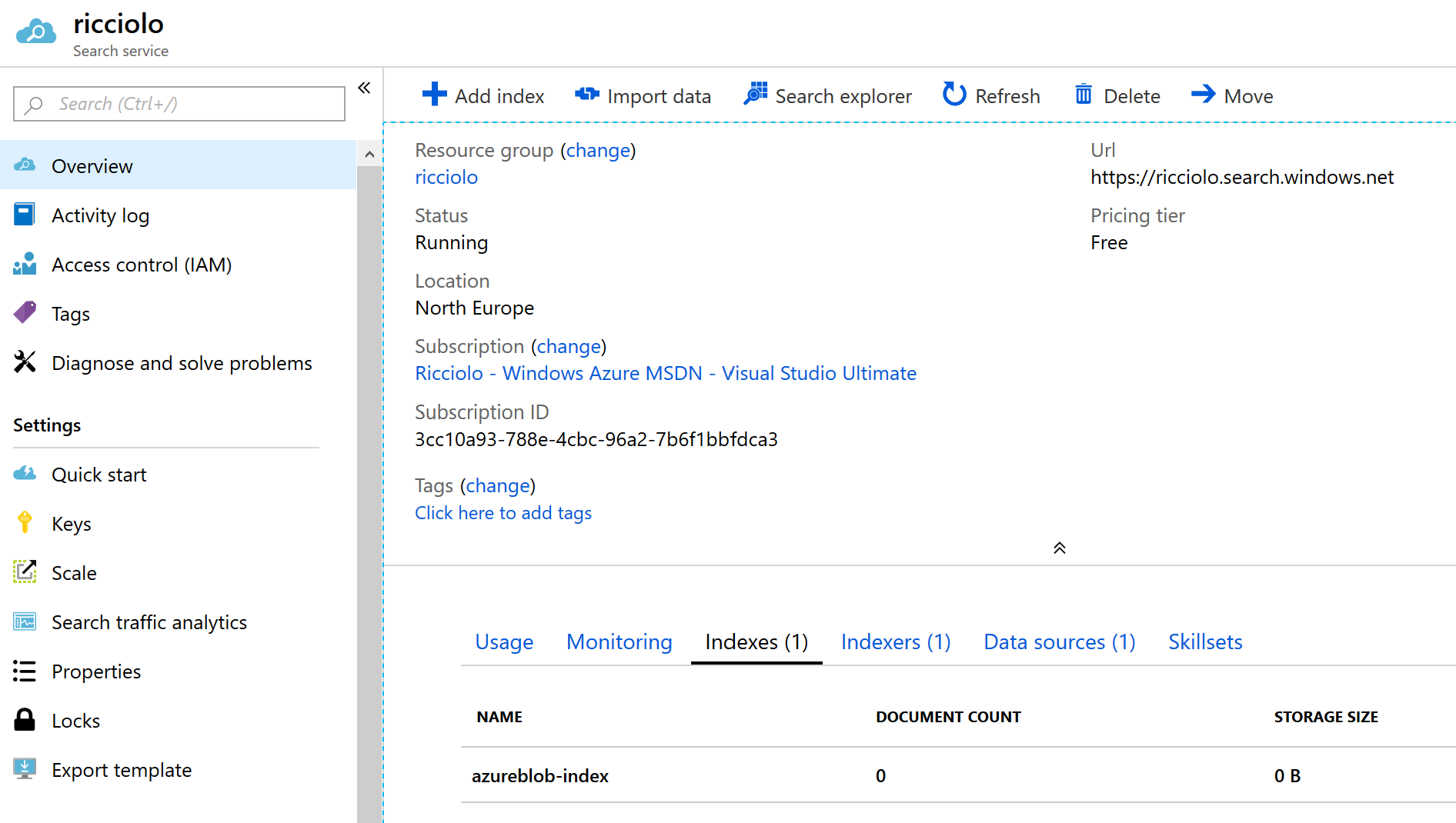
Premendo sull'indexer possiamo forzare l'esecuzione del motore, mentre accedendo all'index possiamo procedere ad un'interrogazione dell'indice.
Commenti

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
Approfondimenti
Sfruttare MQTT in cloud e in edge con Azure Event Grid
Creazione di componenti personalizzati in React.js con Tailwind CSS
Personalizzare l'errore del rate limiting middleware in ASP.NET Core
Utilizzare Model as a Service su Microsoft Azure
Utilizzare il trigger SQL con le Azure Function
Miglioramenti nelle performance di Angular 16
Sostituire la GitHub Action di login su private registry
Gestire liste di tipi semplici con Entity Framework Core
Utilizzare un service principal per accedere a Azure Container Registry
Copiare automaticamente le secret tra più repository di GitHub
Gestire undefined e partial nelle reactive forms di Angular
I piů letti di oggi
- Utilizzare WebAssembly con .NET, ovunque
- ecco tutte le novità pubblicate sui nostri siti questa settimana: https://aspit.co/wkly buon week-end!
- Ottimizzare le performance delle collection con le classi FrozenSet e FrozenDictionary
- Utilizzare il trigger SQL con le Azure Function
- Disabilitare automaticamente un workflow di GitHub (parte 2)
- Ottimizzazione dei block template in Angular 17
- Paginare i risultati con QuickGrid in Blazor



 7")